

pyocrで画像からテキストを抽出します。
Colabで検証するため、Google Colaboratoryの環境がない方は以下を参考にしてください。

pyocrの環境構築
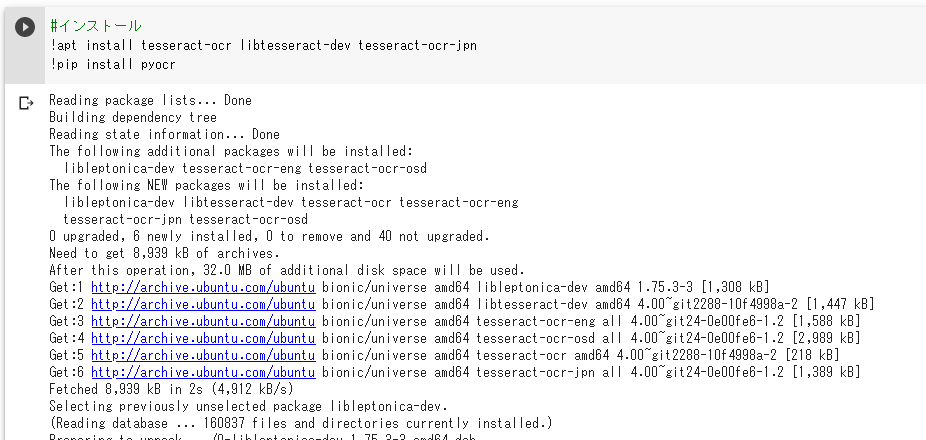
まずはpyocrを使用するために必要なものをインストールします。
!apt install tesseract-ocr libtesseract-dev tesseract-ocr-jpn
!pip install pyocr
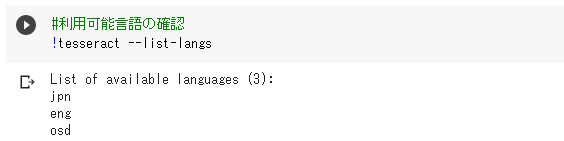
tesseractで利用できる言語を確認します。
日本語が書かれた画像を使用するため「jpn」が出力されることを確認します。
!tesseract –list-langs
tesseractですがMac環境でいくつか動作検証をしています。
興味のある方はこちらの記事も参照してみてください。

pycorに必要なモジュールをインポートします。
ここではpyocrと画像を読み込むためにPIL(PythonImagingLibrary)の
Imageモジュールをインポートします。
from PIL import Image
import pyocr

pyocrが利用可能か確認します。
tools = pyocr.get_available_tools()
tool = tools[0]
print(“Will use tool ‘%s'” % (tool.get_name()))
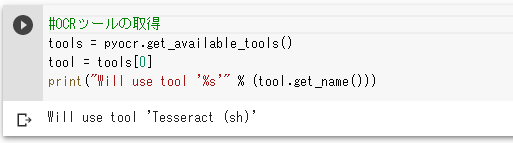
「Will use tool ‘Tesseract (sh)’」と出力されれば問題ないですが
「list index out of range」のエラーが出力された際はtesseractが正常にインストールされていない可能性があります。
pyocrによる画像からテキストの抽出
次にテキストを抽出したい画像を読み込みます。
img1 = Image.open(“img1.png”)
img2 = Image.open(“img2.png”)
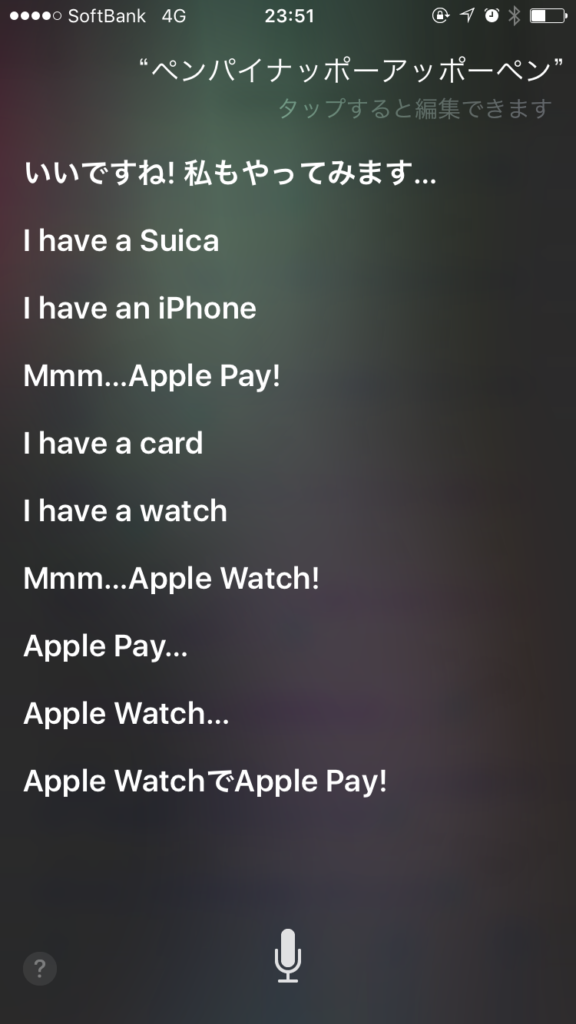
今回はsiriから出力されたテキストと手書きのテキストの2つを読み込みました。
siriから出力されたテキスト(img1)
手書きのテキスト(img2)

img1の画像からテキストを抽出します。
txt1 = tool.image_to_string(img1, lang=”jpn”, builder=pyocr.builders.TextBuilder(tesseract_layout=3))print(txt1)
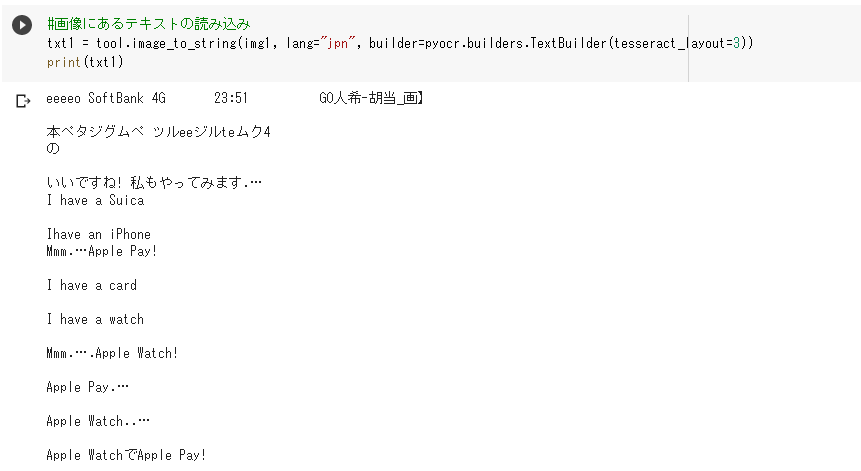
「ペンパイナッポーアッポーペン」が上手く読み取れなかったり、
「タップすると編集できます」の文字が背景と区別が付きづらいのか認識されていません。
次にimg2の画像からテキストを抽出します。
txt2 = tool.image_to_string(img2, lang=”jpn”, builder=pyocr.builders.TextBuilder(tesseract_layout=3))print(txt2)

何も出力されませんでした。
こういったときは「tesseract_layout=」の値を変更してみます。
(tesseract_layoutのデフォルトは3です。)

「tesseract_layout=6」にしたところひらがなはまあまあな精度で認識してくれましたが
カタカナは課題が残りました。
「tesseract_layout」に指定する値は0~13までの値を指定することができるようです。
それぞれの値の意味は以下の記載が答えかと思います。
ただ、勉強不足で申し訳ございませんが意味を理解することはできておらず
最良の結果をもたらすにはどの値が適切かは私のほうでアイディアを持っていません。
画像から上手くテキストを出力できない場合はtesseract_layoutの値を順繰り試しています。
https://github.com/tesseract-ocr/tessdoc/blob/master/ImproveQuality.md#page-segmentation-method
辞書を変えて実行してみる
tessdataは3種類存在するようです。

インストール時はtessdata_fastの日本語が格納されているようです。
格納先は以下コマンドで確認してみます。
!find /usr -name tessdata

上記ディレクトリにある「\jpn.traineddata」を
以下tessdata_bestの辞書をダウンロードし、上書きします。
https://github.com/tesseract-ocr/tessdata_best/blob/master/jpn.traineddata
再度画像を読み込み、テキストを抽出します。
txt1_best = tool.image_to_string(img1, lang=”jpn”, builder=pyocr.builders.TextBuilder(tesseract_layout=3))print(txt1_best)
print(“——————————-“)
txt2_best = tool.image_to_string(img2, lang=”jpn”, builder=pyocr.builders.TextBuilder(tesseract_layout=6))print(txt2_best)
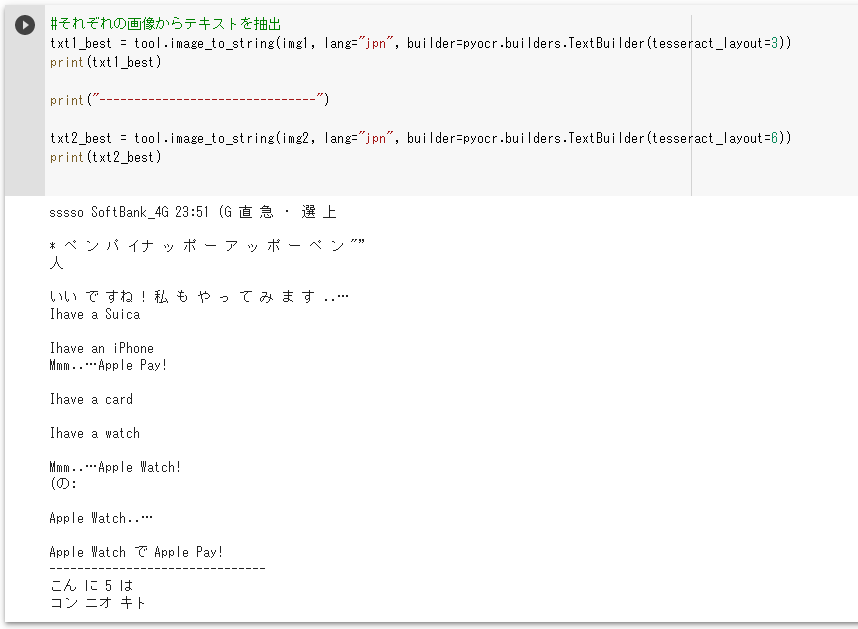
img1は「ペンパイナッポーアッポーペン」が認識されましたが
余計な文字もいくつか散見されます。
img2はひらがなは前回と変わらずでカタカナが少し改善されました。
もう一つ試してみましょう。
以下をダウンロードし、アップロードします。
https://github.com/tesseract-ocr/tessdata/blob/master/jpn.traineddata
txt1_trained = tool.image_to_string(img1, lang=”jpn”, builder=pyocr.builders.TextBuilder(tesseract_layout=3))print(txt1_trained)
print(“——————————-“)
txt2_trained = tool.image_to_string(img2, lang=”jpn”, builder=pyocr.builders.TextBuilder(tesseract_layout=6))print(txt2_trained)

数字が①などに置き換わってしまっていますね。
画像を加工して実行
最後に画像を加工して読み取り精度が向上するか検証してみます。
今回は画像の色を反転させて検証してみます。
from PIL import ImageOps

画像の色を反転させるにはImageOps.invert()を使用します。
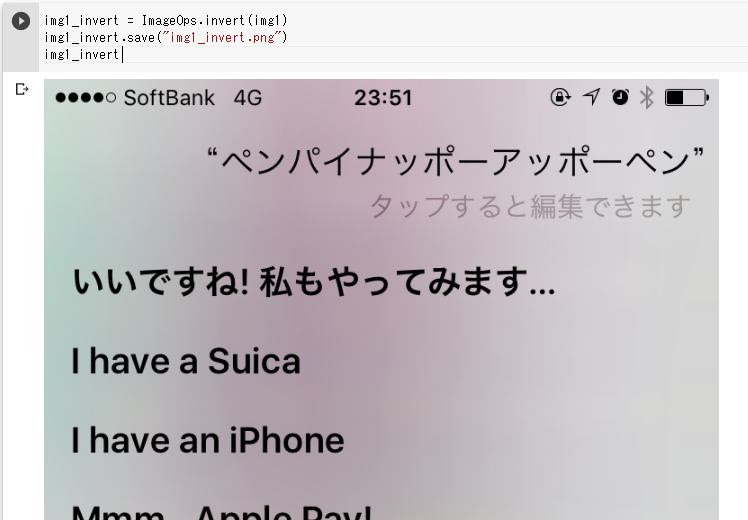
img1_invert = ImageOps.invert(img1)
img1_invert.save(“img1_invert.png”)
img1_invert
img2_invert = ImageOps.invert(img2)
img2_invert.save(“img2_invert.png”)
img2_invert

色を反転させた画像からテキストを抽出します。
(tessdata_bestの日本語辞書を使用しました。)
txt1_invert = tool.image_to_string(img1_invert, lang=”jpn”, builder=pyocr.builders.TextBuilder(tesseract_layout=3))print(txt1_invert)
print(“——————————-“)
txt2_invert = tool.image_to_string(img2_invert, lang=”jpn”, builder=pyocr.builders.TextBuilder(tesseract_layout=6))print(txt2_invert)

img1は薄い色の「タップすると編集できます」が読み取れませんがなかなか精度が良いです。
img2(手書き文字)は色を黒から白にしたことでひらがなが上手く抽出することができませんでした。


コメント