

Python のlxmlライブラリにあるhtmlパッケージでHTMLファイルからデータを取得する方法を紹介します。
また、HTMLファイルから日本語を取得しようとすると日本語が文字化けします。
文字化けにはcodecsモジュールを用いた解消方法を記載しております。
検証用としてHTMLファイルを用意します。
lxmlのインストール
pipコマンドでlxmlライブラリをインストールします。
>pip install lxml

HTMLファイルからデータの取得(read)
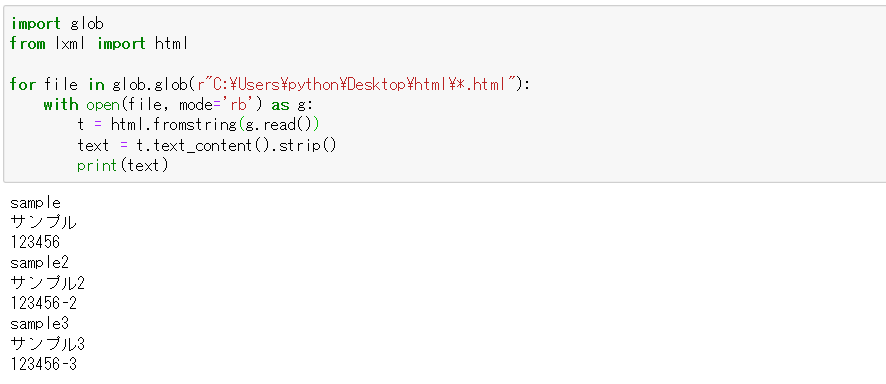
import glob
from lxml import html
for file in glob.glob(r"C:\Users\python\Desktop\html\test.html"):
with open(file, mode='rb') as g:
t = html.fromstring(g.read())
text = t.text_content().strip()
print(text)
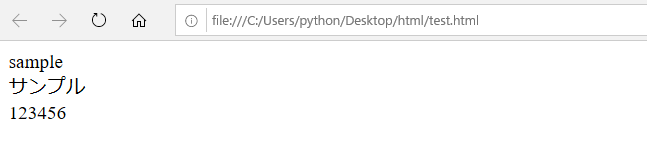
上記コマンドを実行すると以下のように出力されます。

text_content()はテキストコンテンツをマークアップなしで返してくれます。
この記述がないと「<Element html at 0x1f355a9d680>」というように返されます。
4行目のfor~で処理をループさせることで同フォルダに入れた複数のHTMLファイルを
一度に実行することができます。
HTMLファイルからデータの取得(readlines)文字化け対応
read()でHTMLファイルを読み込むと日本語も正しく日本語表示されますが
readlines()で日本語部分を取得しようとすると文字化けが発生します。

日本語が文字化けしてしまった場合はcodecsモジュールで解消します。
import glob
import codecs
from lxml import html
for file in glob.glob(r"C:\Users\python\Desktop\html\test.html"):
with open(file, mode='rb') as g:
t = html.fromstring(g.readlines()[7].decode('utf_8'))
text = t.text_content().strip()
print(text)

上記のように日本語が文字化けしているときはデコードさせましょう。
codecs.decodeで「utf_8」を指定して元の日本語文字に復元させることができました。


タイトルとURLをコピーしました
コメント