

今回は MeCab をインストールして日本語の wordcloud を作成します。
MeCab はオープンソースの形態素解析エンジンで
英語のようにスペース区切りの文章ではない日本語でも的確に単語を抽出してくれます。
本検証は以前投稿している Ubuntu20.04 で実施しています。
【Python】ubuntu20.04にPython3.9.1をインストールしてみた
Ubuntu20.04
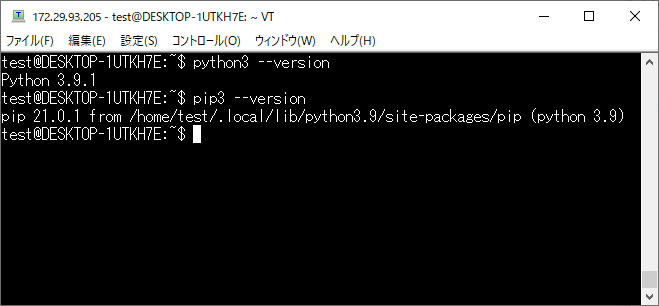
python 3.9.1
pip 21.0.1
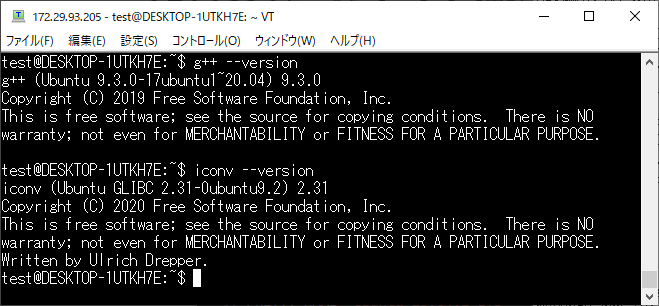
また、 MeCab は以下も必要となりますのでインストールされていない場合は
sudo apt install ●●●でインストールしておきましょう。
g++ 9.3.0
iconv 2.31
MeCab のダウンロード
赤枠のダウンロードリンクから Mecab と辞書をダウンロードします。

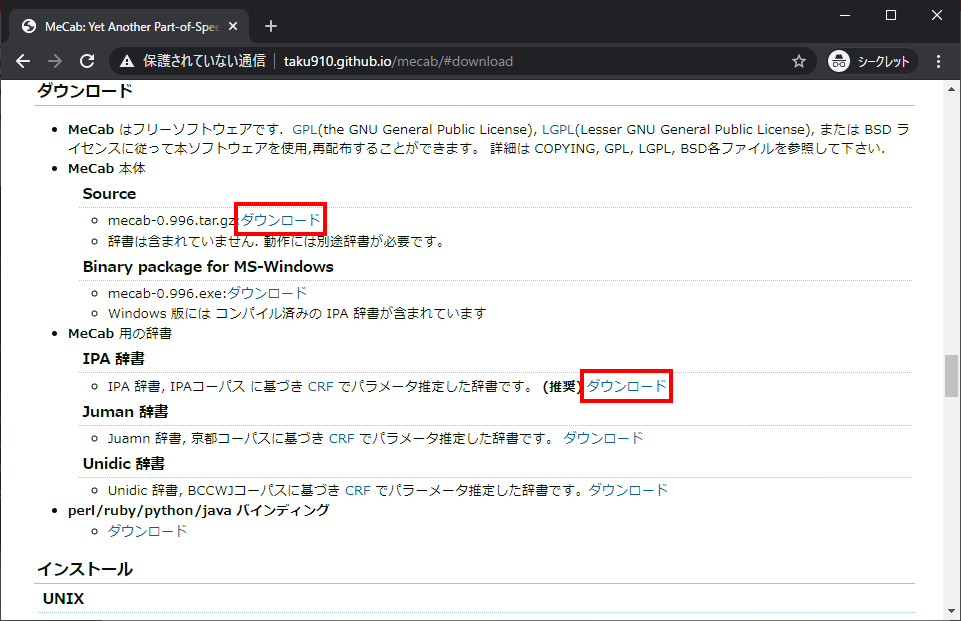
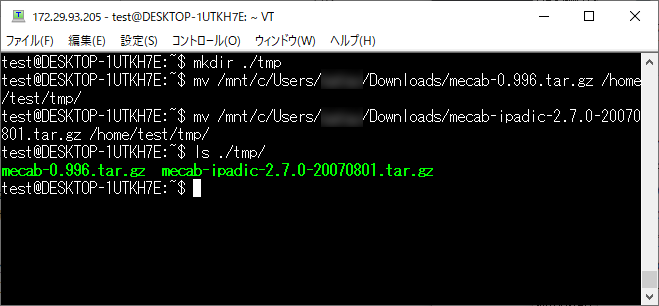
ダウンロードした MeCab 本体と辞書を任意の作業場所に格納します。
MeCab のインストール
MeCab 本体を解凍します。
cd ./tmp
tar -xzvf mecab-0.996.tar.gz
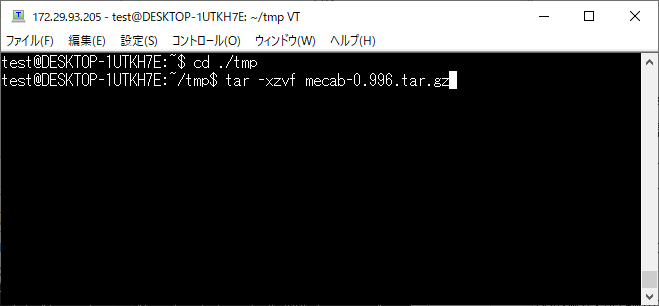
解凍すると[mecab-0.996]フォルダが作成されるので移動して MakeFile を作成します。
cd ./mecab-0.996/
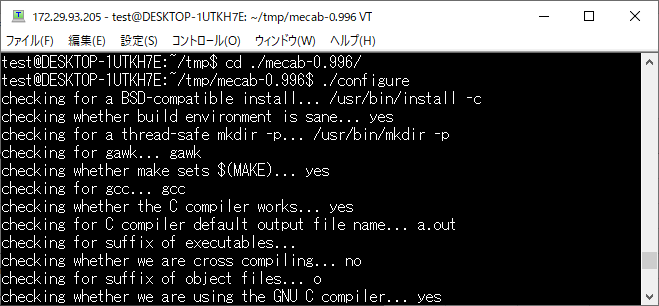
./configure
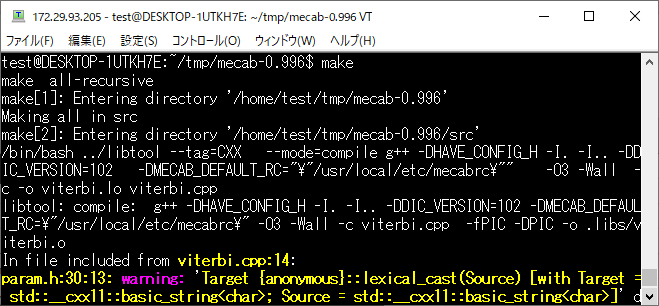
make します。
make
MeCab をインストールします。
sudo make install
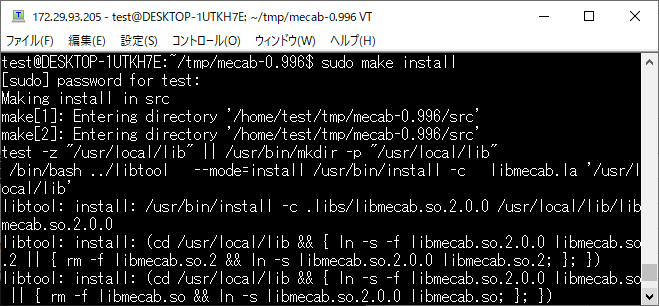
MeCab の辞書のインストール
MeCab の辞書も同様にインストールしていきますが注意点がありますので
解決方法も説明していきます。
MeCab の辞書ファイルを解凍します。
cd ../
tar -xzvf mecab-ipadic-2.7.0-20070801.tar.gz
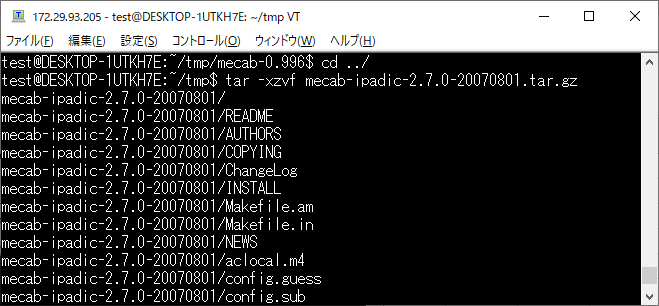
解凍すると[mecab-ipadic-2.7.0-20070801]フォルダが作成されるので移動して
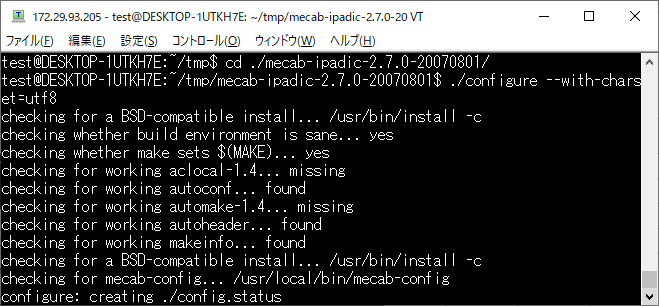
MakeFile を作成します。(ここではデフォルトで指定される文字コードをutf-8にします)
cd ./mecab-ipadic-2.7.0-20070801/
./configure –with-charset=utf8
make をそのままやるとエラーになります。。。
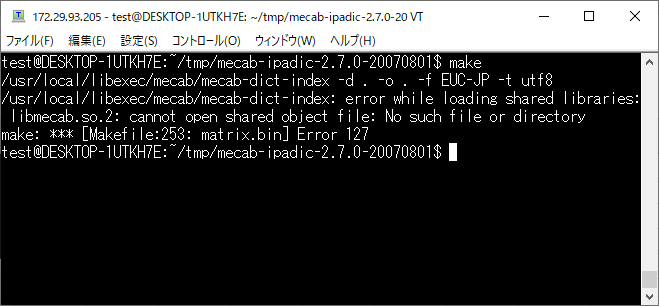
/usr/local/libexec/mecab/mecab-dict-index: error while loading shared libraries: libmecab.so.2: cannot open shared object file: No such file or directory
make: *** [Makefile:253: matrix.bin] Error 127
どうも共有ライブラリを認識させてあげる必要があるので以下コマンドを実行します。
sudo ldconfig
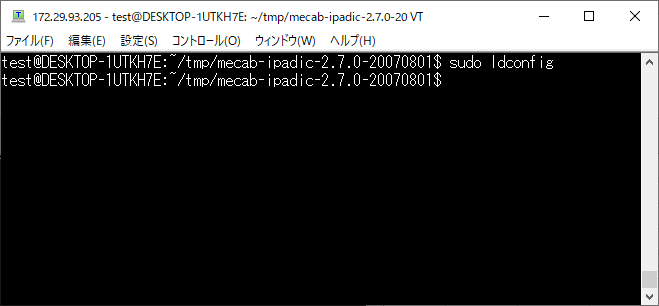
make コマンドを実行してエラーが発生しないことを確認します。
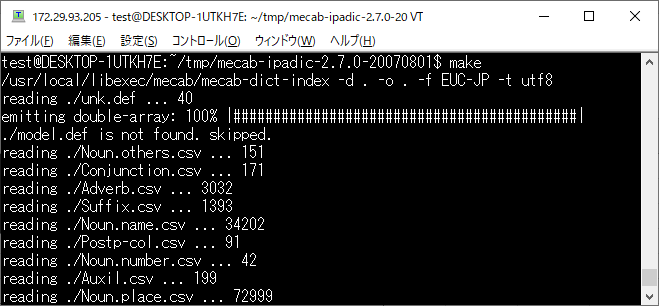
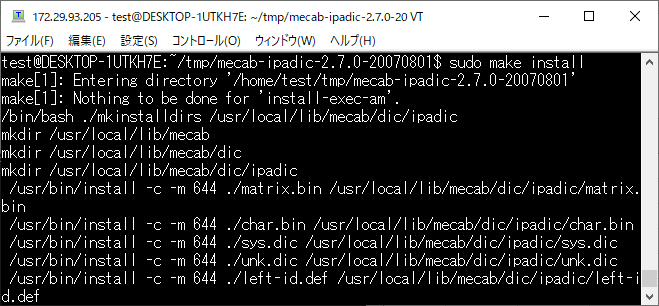
MeCab の辞書をインストールします。
sudo make install
MeCab の動作検証
インストールした MeCab を試してみます。
mecab
これはテストです。
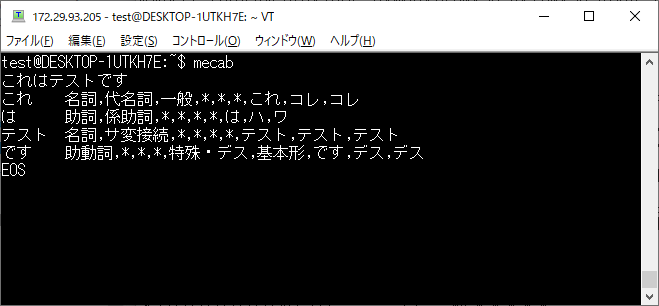
[mecab] と入力し、[Enter]を押下すると
文字を入力することができるので任意の文字列を入力し、[Enter]を押下します。
すると上記画面の通り、日本語文章を分解してくれます。
日本語フォントのインストール
まず日本語フォントが環境にインストールされているか確認しましょう。
fc-list
※デフォルトではインストールされていないはずなので
「sudo apt install fontconfig」を実行してください。
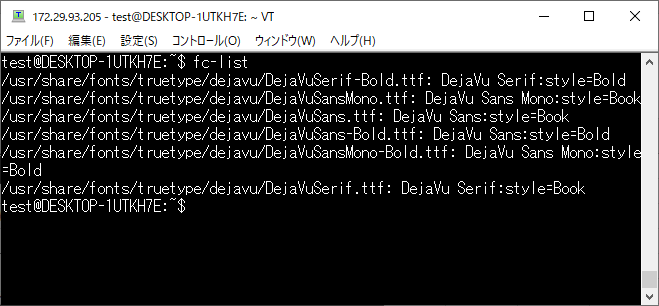
今回はIPAフォントをインストールします。
sudo apt install fonts-ipaexfont
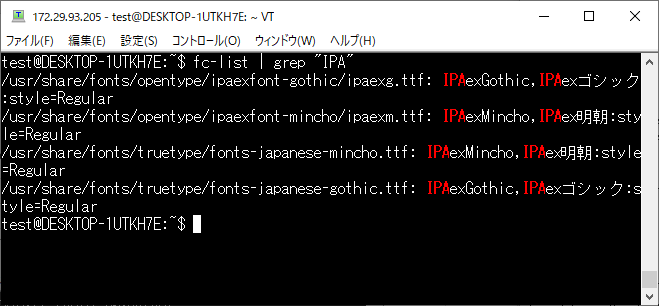
もう一度、fc-listを実行してIPAフォントがインストールされたことを確認します。
fc-list | grep “IPA”
Python で MeCab をインストール
pip で MeCab をインストールします。
pip3 install –user mecab-python3
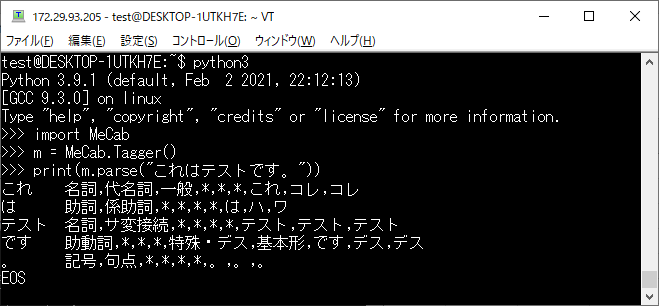
簡単にテストを実行してみます。
import MeCab
m = MeCab.Tagger()
print(m.parse(“これはテストです。”))
事前に以下もインストールしておきましょう。
pip3 install wordcloud matplotlib
Python で日本語の wordcloud を作成する
Python でも MeCab を利用できるようになったので
いよいよ日本語の wordcloud を作成していきます。
今回は Ubuntu なのでデスクトップ環境が必要です。
Xming等で結果を出力させましょう。
Xming の使い方は以下を参考にしてください。
サンプルコードは以下です。
import os
from os import path
from wordcloud import WordCloud
from MeCab import Tagger
import matplotlib.pyplot as plt
import re
d=path.dirname(file) if “file” in locals() else os.getcwd()
text = open(path.join(d, “test.txt”), encoding=”utf-8″).read()
m = Tagger()
m_text = m.parse(text)
re_m_text = re.sub(“\t.*”,””, m_text)
wordcloud = WordCloud(font_path=”/usr/share/fonts/truetype/fonts-japanese-gothic.ttf”,max_font_size=60).generate(re_m_text)
plt.figure()
plt.imshow(wordcloud, interpolation=”bilinear”)
plt.axis(“off”)
plt.show()
test.txt内の文章は 青空文庫 にある文章を一部引用したものとなります。
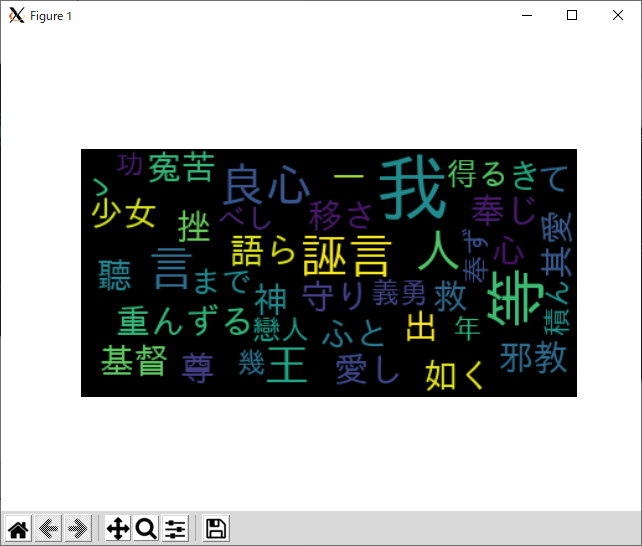
日本語の wordcloud が作成されるか実行してみましょう。
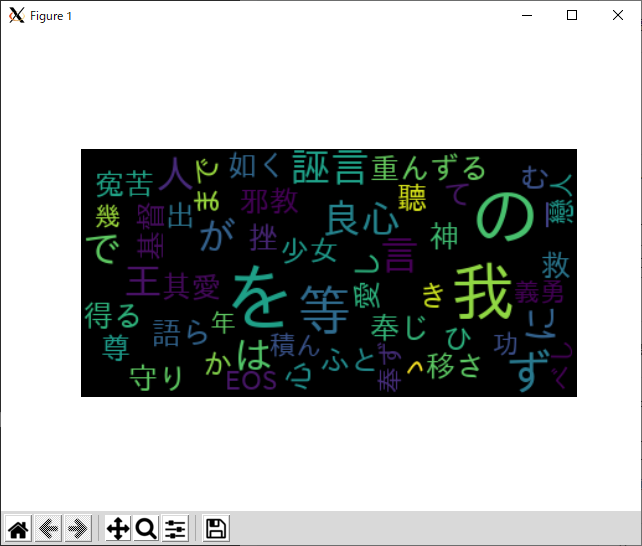
日本語で表示されることを確認しました。
作成された wordcloud を見て、不要な単語があれば
stopwords を入れて調整していきましょう。


コメント